<남여 성별 인구 비율 표현하기>
bar형 그래프
import os
import pandas as pd
import matplotlib.pyplot as plt
def load_csv(name:str) -> pd.DataFrame:
try:
df = pd.read_csv(name, encoding="cp949") #윈도우에서 작성된 파일이기 때문에 기본 구성이 cp949입니다. 리눅스에서는 utf-8을 사용합니다. 그렇기 때문에, 아래서 다시 선언합니다.
print(f"'{os.path.basename(name)}'이 로드되었습니다.")
return df
except FileNotFoundError as e:
print("해당 파일이 존재하지 않습니다.")
return pd.DataFrame("[[]]")
def load_csv()함수는 csv파일을 불러오는 함수다.
try를 이용하여 예외 처리를 하여 프로그램의 에러를 잡는다.
def jeju_pop():
df = load_csv("../data/gender.csv")
print(df)
m = []
f = []
name = input('찾고 싶은 지역의 이름을 입력하세요. : ')
for idx, row in df.iterrows():
if name in row.iloc[0]:
for i in row.iloc[3:104]:
m.append(-int(i))
for i in row.iloc[106:]:
f.append(int(i))
break
plt.style.use('ggplot')
plt.figure(figsize=(10,5), dpi=300)
plt.rc('font', family='Malgun Gothic')
plt.rcParams['axes.unicode_minus'] = False
plt.title(name+'Gender Population distribution')
plt.barh(range(101), m, label='Man')
plt.barh(range(101), f, label='Woman')
plt.legend()
plt.show()
iterrows() 함수를 사용하면 DataFrame의 각 행을 반복하면서 해당 행의 인덱스와 행 데이터를 받을 수 있다.
for index, row in df.iterrows():의 형태로 쓰인다.
데이터 프레임의 행이나 칼럼의 순서를 나타내는 정수로 특정 값을 추출해오는 방법이다
iloc
iloc는 0부터 시작하는 인덱스를 사용하며, 슬라이싱도 지원한다.
df.iloc[0]은 첫 번째 행을 반환하고, df.iloc[:, 0]은 첫 번째 열을 반환한다
# 첫 번째 행 출력
row_1 = df.iloc[0]
print(row_1)# 두 번째 열 출력
col_2 = df.iloc[:, 1]
print(col_2)# 첫 번째 행, 두 번째 열의 값 출력
value = df.iloc[0, 1]
print(value)
pie형 그래프
def want_pop():
df = load_csv("../data/gender.csv")
size = []
name = input('찾고 싶은 지역의 이름을 입력하세요. : ')
for idx, row in df.iterrows():
if name in row.iloc[0] :
m = 0
f = 0
for i in range(101) :
m += int(row.iloc[i+3])
f += int(row.iloc[i+106])
break
size.append(m)
size.append(f)
color = ['crimson', 'yellow']
plt.axis('equal')
plt.pie(size, labels = ['Male','Female'], autopct = '%.1f%%', colors=color, startangle=90)
plt.title("Male and female population distribution in the region")
plt.show()

def main() -> None:
# jeju_pop()
want_pop()
if __name__ == "__main__":
main()
타이타닉을 이용한 그래프 생성
import os
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
def load_csv(name:str) -> pd.DataFrame:
try:
df = pd.read_csv(name, encoding="cp949") #윈도우에서 작성된 파일이기 때문에 기본 구성이 cp949입니다. 리눅스에서는 utf-8을 사용합니다. 그렇기 때문에, 아래서 다시 선언합니다.
print(f"'{os.path.basename(name)}'이 로드되었습니다.")
return df
except FileNotFoundError as e:
print("해당 파일이 존재하지 않습니다.")
return pd.DataFrame("[[]]")
def survived_probability():
df=load_csv('../data/titanic.csv')
size = []
print(len(df[df['Survived'] == 1]))
print(len(df[df['Survived'] == 0]))
live = len(df[df['Survived'] == 1])
die = len(df[df['Survived'] == 0])
size.append(live)
size.append(die)
color = ['crimson', 'yellow']
plt.axis('equal')
plt.pie(size, labels=['live', 'die'], autopct='%.1f%%', colors=color, startangle=90)
plt.title("survive")
plt.show()
def survive_gender():
df = load_csv('../data/titanic.csv')
size = []
print(len(df[(df['Survived'] == 1) & (df['Sex'] == 'male')]))
print(len(df[(df['Survived'] == 1) & (df['Sex'] == 'female')]))
live_male = len(df[(df['Survived'] == 1) & (df['Sex'] == 'male')])
live_female = len(df[(df['Survived'] == 1) & (df['Sex'] == 'female')])
size.append(live_male)
size.append(live_female)
color = ['crimson', 'yellow']
plt.axis('equal')
plt.pie(size, labels=['male', 'female'], autopct='%.1f%%', colors=color, startangle=90)
plt.title("male vs female")
plt.show()
def titanic_prob(target:str, live:bool=True, graph:str="pie"): #target은 원하는 컬렴명.
df = load_csv('../data/titanic.csv')
if live: a, b = "Live", 1
else: a, b = "Die", 0
size = []
unique_value = df[target].unique() #unique()라는 함수는 pandas에서 제공하는 메서드함수로, 유일한 값을 찾는데 사용되는 함수이다.
unique_value_ = unique_value[~pd.isnull(unique_value)] #pd는 pandas에서 제공하는 메서드 함수이며, '~'는 not을 의미한다. isnull은 널인 것 즉, 널이 아닌 것만 선별하여 다시 변수에 저장한다는 의미이다.
for v in unique_value_:
v1 = len(df[(df['Survived'] == b) & (df[target] == v)])
size.append(v1)
#기본 그래프 모양은 pie
if graph == "pie":
plt.pie(size, labels=unique_value_, autopct='%.1f%%', startangle=90)
plt.title(f"{target} {a} Prob.")
plt.show()
#마지막 인자에 "bar"를 추가하면 그래프형식으로 바꿔준다.
elif graph == "bar":
plt.bar(unique_value_, size)
plt.title(f"{target} {a} Prob.")
plt.show()
df.plot(kind='bar', figsize=(10, 5), stacked=True)
plt.xlabel('age_cat')
plt.ylabel('rate')
plt.show()
print(df.head())
def main() -> None:
# survived_probability()
# survive_gender()
titanic_prob("Age", True, "bar")
if __name__ == "__main__":
main()
타이타닉 생존자 중 Age 컬럼을 bar형 그래프로 출력하고 싶을 때
def main() -> None:
titanic_prob("Age", True, "bar")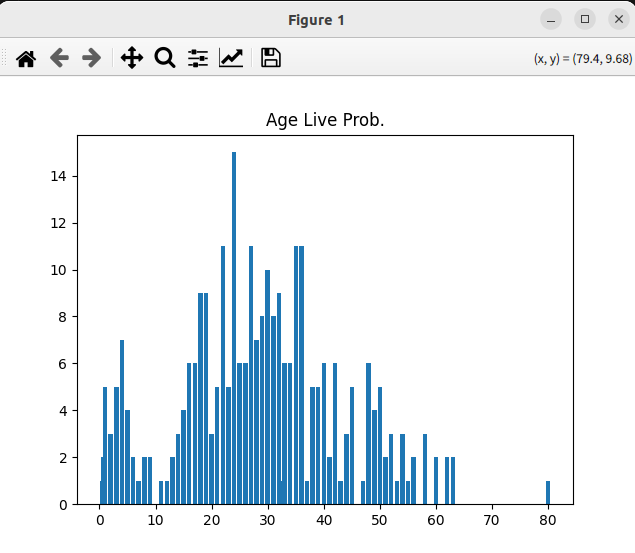
타이타닉 생존자 중 Embarked을 pie형으로 출력하고 싶을 때
def main() -> None:
titanic_prob("Embarked", True)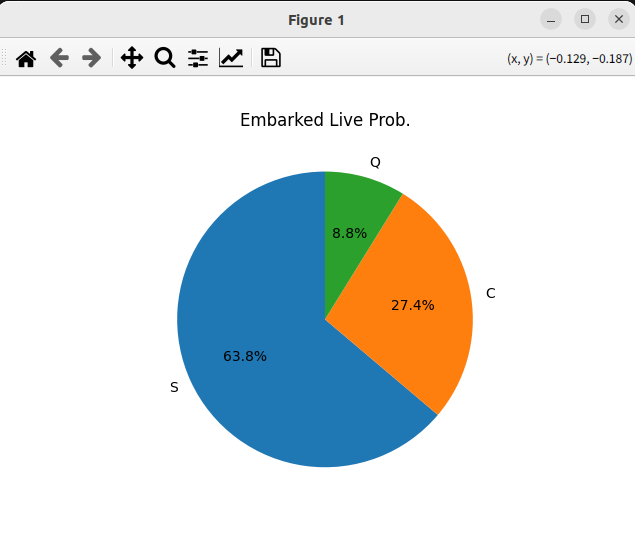
타이타닉 생존자 중 Sex를 pie형으로 출력하고 싶을 때
def main() -> None:
titanic_prob("Sex", True)
'데이터베이스' 카테고리의 다른 글
| 프로시저와 트리거 (0) | 2024.09.20 |
|---|---|
| 수강신청 DB만들어보기 (0) | 2024.09.08 |
| DB 만들어보기 (0) | 2024.09.06 |
| Data Base (0) | 2024.08.18 |

댓글